The Efficiency Algorithm: Using Zipf's Law to Hack Vocabulary
Imagine you walk into a library with 100,000 books. You want to read them all. But you only have time to read 100 pages. Which pages do you read?
Most language learners read random pages. They learn "Colors" (Blue, Red, Green). They learn "Animals" (Dog, Cat, Owl). They learn "Kitchen Items" (Fork, Spoon, Spatula).
This feels logical. But mathematically, it is a disaster.
Language is not linear. It is exponential. In this guide, we will explore Zipf's Law, the "Power Law" distribution of vocabulary, and why the word "The" is worth 1,000 times more than the word "Owl."
Part 1: What is Zipf's Law?
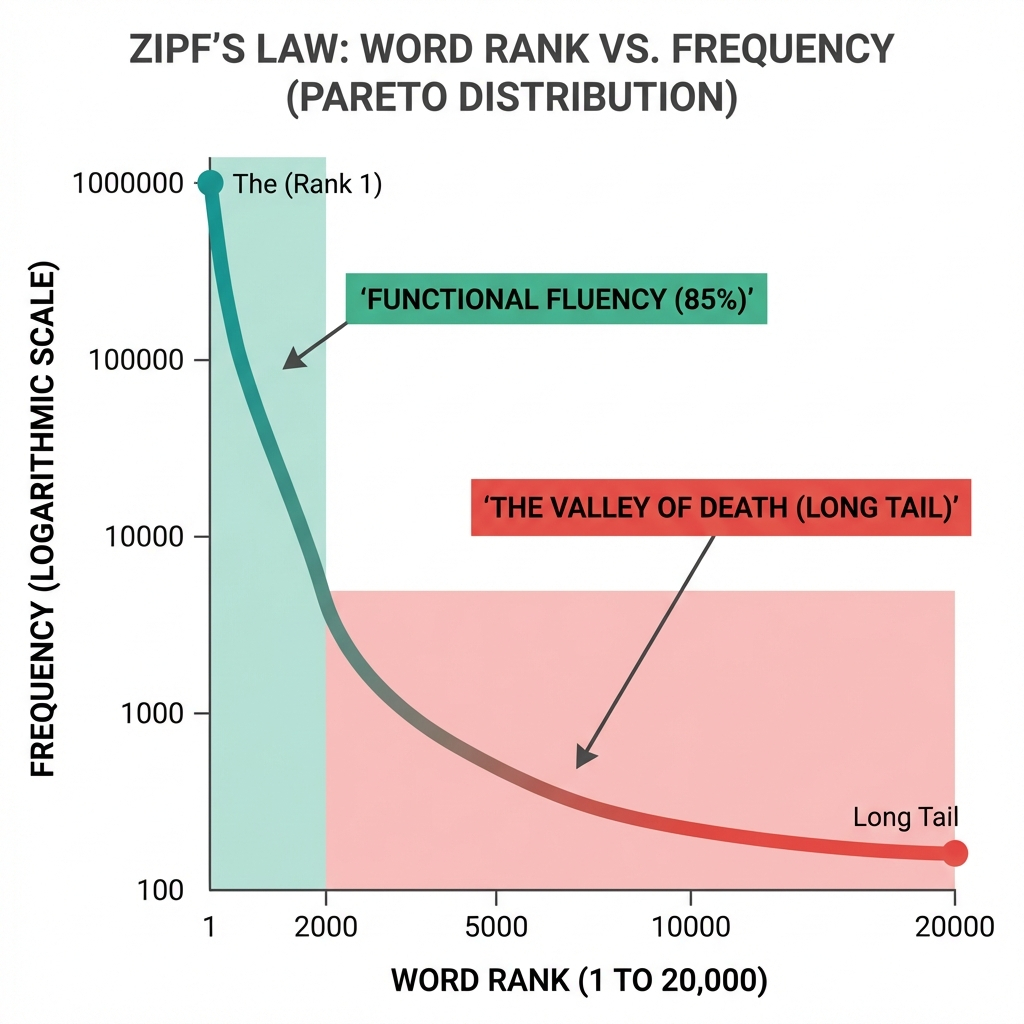
In 1935, linguist George Kingsley Zipf noticed a pattern. If you count every word in a book, the incidence of a word is inversely proportional to its rank.
- Rank 1 (Most common word): Appears N times.
- Rank 2: Appears N/2 times.
- Rank 3: Appears N/3 times.
The Data: In English:
- "The" (Rank 1): ~7% of all words.
- "Of" (Rank 2): ~3.5% of all words.
- "And" (Rank 3): ~2.3% of all words.
The Implication: If you learn just 135 words, you account for 50% of all spoken language. If you learn 2,000 words, you account for 85%. To go from 85% to 95%, you need to learn 10,000 more words.
This is the Law of Diminishing Returns. The "Return on Investment" (ROI) for the first 1,000 words is astronomical. The ROI for the next 10,000 is tiny.
Part 2: The "Fluency Trap" (The Long Tail)
Why is language learning so hard? Because of the Long Tail.
You can learn the Top 2,000 words in 3 months. You can say: "I want to go to the house to eat food." But you cannot say: "The squeaky hinge on the cupboard needs to be lubricated."
"Squeaky", "Hinge", "Cupboard", "Lubricated". These are Rank 5,000+ words. They appear maybe once every 1,000,000 words. But they carry 100% of the meaning in that specific sentence.
The Trap: Beginners focus on the Head (The, Of, And). They feel fluent quickly. Then they hit real life (The Long Tail). They realize they know nothing. The gap between "Conversational" (2,000 words) and "Native" (20,000 words) is the "Valley of Death."
Part 3: The "Frequency List" Strategy
How do we cross the Valley of Death efficiently? We stop learning random words. We stop using Duolingo categories ("Zoo Animals"). We use Frequency Lists.
A Frequency List is a dataset sorted by Zipf rank.
- A1 Level: Top 500 words.
- A2 Level: Top 1,000 words.
- B1 Level: Top 2,000 words.
The Algorithm:
- Download the "Top 5000 Spanish Words" list (e.g., from a Corpus like Wiktionary).
- Start at #1. Do you know it? Yes. Delete.
- Go to #543 ("Developing"). Do you know it? No. Learn this.
- Go to #5000 ("Proclivity"). Do you know it? No. Ignore this.
Why ignore #5000? Because you will likely never hear "Proclivity" in a Spanish bar. Spending brain energy to memorize it is "Inefficient Allocation of Resources." Your brain has limited glucose. Spend it on #543.
Part 4: Function Words vs Content Words
There is a catch to Zipf's Law. The Top 100 words are Function Words (The, Is, At, On). They hold grammar together, but they have no "Image." You cannot visualize "Of."
The words from Rank 101-2000 are mostly Content Words (Table, Run, Happy, Blue). Content Words carry the story.
The "Tarzan" Phase: If you only know Content Words, you sound like Tarzan: "Me... Hunger... Eat... Cow." People understand you perfectly. If you only know Function Words, you sound like a lawyer having a stroke: "The... of... is... at... on... be." People understand nothing.
Strategy: Prioritize Content Words (Verbs/Nouns) first. Don't obsess over Prepositions ("Por vs Para") early on. They are high frequency, but low utility for survival.
Part 5: Domain Specificity (The "Jargon" Bubble)
Zipf's Law changes based on Context. The "General English" Zipf curve is different from the "Medical English" Zipf curve.
In a hospital:
- Rank 1: "Patient"
- Rank 2: "Dose"
- Rank 3: "Blood"
If you are a doctor moving to Germany, typical language apps are useless. They teach you "Train Station." You need "Intravenous." You need a Domain-Specific Frequency List.
Text Clarifier's Role: This is where our tool shines. If you read predominantly Tech News, Text Clarifier will constantly clarify words like "Algorithm," "Latency," "Deprecated." You are naturally building a frequency list tailored to your life, not a generic list tailored to a tourist.
Part 6: The Pareto Principle (80/20 Rule)
Zipf's Law is just a linguistic version of the Pareto Principle. 80% of the results come from 20% of the causes. 80% of speech comes from 20% of the vocabulary.
The Optimization: Identify the "Vital Few." What are the words you use?
- Do you talk about philosophy? Learn "Existential."
- Do you talk about soccer? Learn "Offside."
Create a "Personal Frequency List." Record yourself speaking English for a day. Transcribe it. Count the words. Translate those words to Spanish. That is your "Identity Map." Learn that first.
Part 7: Conclusion: Be a Data Scientist
Stop being a "Student." Be a "Linguistic Engineer." Don't open a textbook and start at Chapter 1. Look at the data. Optimize your path.
If you spend 10 hours learning the names of "Zoo Animals" (Lion, Tiger, Bear), you have wasted 10 hours. Unless you work at a Zoo. In which case, ignore everything I just said.
References:
- Zipf, G. K. (1935). The Psycho-Biology of Language.
- Nation, I. S. P. (2001). Learning Vocabulary in Another Language.
- Pareto, V. (1896). Cours d'économie politique.